
Media Mix Modeling in Python: A Step-by-Step Guide
Marketing ROI- it's that number everyone wants, but few can nail down with confidence. If you've ever wondered which of your marketing channels is actually pulling its weight and which is just burning budget, you're not alone. That's where media mix modeling (MMM) comes in. Think of it as your marketing decoder ring, a data-driven method that cuts through the noise and shows you what's really working. No more crossed fingers or gut feelings about whether your latest campaign moved the needle.
Media mix modeling (MMM) in Python is a data-driven approach that helps marketers measure the true impact of various advertising channels on sales and conversions. By leveraging statistical techniques and machine learning, Python-based MMM analyzes historical marketing data to determine which channels drive the highest ROI. This blog explores how to implement media mix modeling in Python, covering key methodologies, tools, and best practices to optimize marketing spend effectively.
This lack of clear attribution can lead to significant financial losses. Budgets get misallocated, potentially high-performing channels get neglected, and overall marketing effectiveness needs to improve.
But there’s a solution. Media mix modeling (MMM), a sophisticated statistical technique, cuts through the ambiguity and delivers data-driven insights into the true impact of your marketing mix. By leveraging the power of Python, you can build a robust MMM model that unveils the hidden ROI of your advertising efforts, you can build a robust MMM model that unveils the hidden ROI of your advertising efforts. This blog serves as your professional guide to unlocking the potential of MMM with Python.
In this guide, we’ll break down how MMM works and show you how to build your own model using Python. By the end, you’ll have a practical framework for turning your marketing decisions from educated guesses into strategic moves backed by real data. Let’s get started.
Key Takeaways
- Media mix modeling in Python enables data-driven marketing decisions by analyzing the impact of different channels on performance.
- High-quality, comprehensive data across all marketing channels is essential for accurate modeling and actionable insights.
- Robust attribution models help assign credit to marketing touchpoints, improving budget allocation and campaign effectiveness.
- Incorporating external factors like seasonality and economic trends prevents bias and enhances model accuracy.
- Balancing complexity and interpretability ensures stakeholders can trust and apply model insights effectively.
- Continuous updates and refinements using new data keep media mix strategies adaptive and optimized for market dynamics.
What is Media Mix Modeling?
Media mix modeling (MMM) is a powerful statistical technique that reveals which marketing efforts actually move the needle. By analyzing historical data, it shows you can see exactly how different channels, campaigns, and strategies contribute to sales and other critical business outcomes.
Core Metrics That Matter
- Reach: How many unique people see your campaign across a given channel.
- Frequency: How often the average person encounters your message.
- Gross Rating Points (GRPs): Your campaign’s total exposure, calculated by multiplying reach times frequency.
- Return on Investment (ROI): The bottom-line measure of profitability—how much revenue your campaigns generate compared to what they cost.
Why Media Mix Modeling Works
- Spend Smarter: Discover which channels deserve more budget and which deserve less, eliminating guesswork from your allocation decisions.
- Make Better Calls: Gain clear visibility into what’s working and what isn’t, so your strategic planning rests on evidence rather than assumptions.
- Boost Returns: Identify your highest-performing tactics and double down on them to maximize ROI.
- Learn from the Past: Turn historical performance into actionable insights that sharpen your future campaigns.
When you use media mix modeling, you’re replacing hunches with hard data—making every marketing dollar work harder toward growth and profitability.
Why Use Python for Media Mix Modeling?
Python has become a preferred choice for marketing mix modeling due to its versatility, extensive libraries, and straightforward syntax. Traditionally, MMM has been the domain of data scientists, requiring significant statistical expertise. However, Python’s comprehensive ecosystem of libraries, particularly lightweight, democratizes MMM, making it accessible to marketing professionals with a basic understanding of data analysis. With the right Knowledge and planning, Implementation becomes more efficient. These libraries act as sophisticated toolkits, automating the intricate statistical calculations behind MMM and allowing you to focus on gleaning actionable insights from the results.
Here are some compelling reasons why Python is well-suited for conducting media mix modeling:
Advantages of Python
- Rich Ecosystem of Libraries:
- Ease of Integration:
- Scalability:
- Flexibility:
- Community Support:
Python offers powerful libraries such as Pandas, NumPy, Stats models, and Scikit-learn, which facilitate data manipulation, statistical analysis, and machine learning.
Python seamlessly integrates with other tools and platforms, making it convenient for data extraction, transformation, and visualization.
Python’s ability to handle large datasets and perform computations efficiently makes it suitable for complex media mix modeling tasks.
From simple linear regressions to advanced machine learning algorithms, Python supports various modeling techniques, allowing marketers to tailor analyses to their needs.
Python boasts a vibrant community of developers and data scientists who contribute to its libraries and offer support through forums and resources.
Setting Up Your Environment
To begin your journey into media mix modeling with Python, you must set up your development environment. This section guides you through the necessary steps for the implementation process, ensuring your system is fully prepared for conducting sophisticated analyses and modeling.
Installing Python
If Python isn’t already installed on your system, follow these steps to get started:
- Download Python:
- Installation:
- Verification:
Visit python.org and download the latest version of Python that is compatible with your operating system.
Run the installer and carefully follow the on-screen prompts to install Python successfully. During installation, select the option to add Python to your system PATH for easier access from the command line.
Open a command prompt (or terminal on macOS/Linux) and type python --version to verify that Python is installed correctly.
Essential Python Libraries for Media Mix Modeling
Python’s strength lies in its libraries that simplify complex tasks. For media mix modeling, these libraries are essential:
- Pandas:
- NumPy:
- Statsmodels:
- Scikit-learn:
- Matplotlib and Seaborn:
Pandas offer robust data structures and tools optimized for data manipulation and analysis tasks.
NumPy supports extensive handling of large, multi-dimensional arrays and matrices alongside a comprehensive suite of mathematical functions tailored for array operations.
Includes statistical models and tests for performing various statistical analyses.
A comprehensive machine learning library that supports various algorithms for regression, classification, clustering, and more.
Matplotlib and Seaborn are Python libraries used to generate a variety of visualizations, including static, animated, and interactive plots.
Installing Python Libraries
Once installed, you can install these libraries using Python’s package manager, pip. In command prompt, add following commands:
pip install pandas numpy statsmodels scikit-learn matplotlib seaborn
This command installs all the necessary libraries for data manipulation, statistical analysis, machine learning, and visualization.
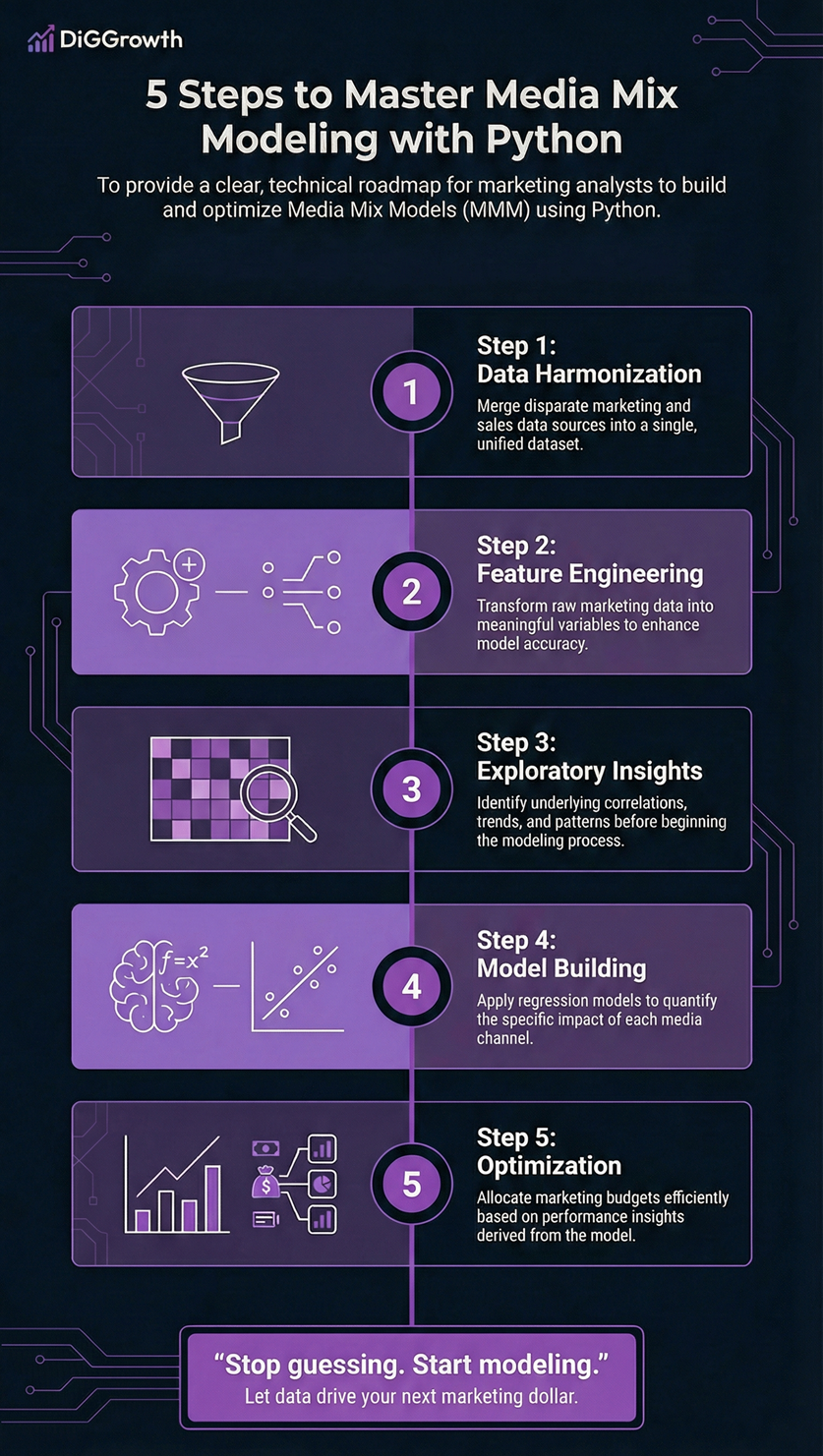
Collecting and Preparing Data
-
Types of Data Required
Effective modeling relies on diverse data such as sales figures, marketing spend, and engagement metrics. Inputs from Sales promotion activities, insights on how content performs with the Search algorithm, and data collected through a Web framework all contribute to accurate and actionable results.
- Media Spend Data:
- Sales Data:
- External Factors:
-
Data Collection Methods
- Internal Sources:
- External Sources:
Gather data from your organization’s databases or marketing platforms where campaign performance metrics and sales data are stored.
Utilize third-party data providers or industry databases to supplement internal data with external factors like market trends, economic indicators, or competitive analyses.
-
Cleaning and Preprocessing Data using Python
- Data Cleaning:
- Data Integration:
- Feature Engineering:
Identify and handle missing values, outliers, and inconsistencies in the data to ensure accuracy and reliability. Python libraries like Pandas offer functions for data cleaning tasks such as handling missing data (fillna, dropna) and outlier detection.
Merge and align data from different sources using unique identifiers (e.g., campaign IDs, date/time stamps) to create a unified dataset for analysis.
Create new variables or features from existing data that may enhance the predictive power of your models. For example, derive metrics like cost per impression or cost per acquisition from media spend and sales data.
Pro Tip- Leverage Business software that incorporates Artificial intelligence to efficiently process large volumes of Web traffic data. This combination enables advanced Predictive modelling, helping you forecast trends, optimize marketing strategies, and make data-driven decisions with greater accuracy.
Detailed records of expenditures across different advertising channels (e.g., TV, radio, digital ads). Ideally, this data should include dates, amounts spent, and the targeted campaigns or channels.
Historical sales performance records over the same period as the media spend data. This can include revenue, units sold, and customer acquisition data.
Additional variables that may influence sales but are not directly controlled by marketing efforts. Examples include economic indicators, seasonality factors, and competitor activities.
Example Python Code Snippet
import pandas as pd
# Load media spend data
media_spend = pd.read_csv('media_spend_data.csv')
# Load sales data
sales_data = pd.read_csv('sales_data.csv')
# Merge datasets
merged_data = pd.merge(media_spend, sales_data, on='date')
# Data cleaning
merged_data['sales'].fillna(0, inplace=True) # Replace missing sales data with 0
# Feature engineering
merged_data['cost_per_sale'] = merged_data['media_spend'] / merged_data['sales']
# Print first few rows of merged dataset
print(merged_data.head())
Exploratory Data Analysis (EDA)
Exploratory Data Analysis (EDA) is crucial in understanding your data and extracting meaningful insights before diving into modeling. In this section, we’ll explore essential techniques and Python tools for conducting EDA in the context of media mix modeling.
Understanding Data Patterns and Trends
- Summary Statistics:
Compute descriptive statistics such as mean, median, standard deviation, and quartiles to summarize the central tendency, dispersion, and shape of your data.
import pandas as pd
# Load merged data (assuming it's already prepared)
merged_data = pd.read_csv('merged_data.csv')
# Summary statistics
summary_stats = merged_data.describe()
print(summary_stats)
- Data Visualization:
Create visual representations of your data using libraries like Matplotlib and Seaborn to identify trends, correlations, and outliers.
import matplotlib.pyplot as plt
import seaborn as sns
# Example: Visualizing media spend and sales relationship
plt.figure(figsize=(10, 6))
sns.scatterplot(x='media_spend', y='sales', data=merged_data)
plt.title('Relationship between Media Spend and Sales')
plt.xlabel('Media Spend')
plt.ylabel('Sales')
plt.show()
- Correlation Analysis:
Calculate correlation coefficients to measure the strength and direction of linear relationships between variables.
# Correlation matrix
correlation_matrix = merged_data.corr()
print(correlation_matrix)
# Heatmap for correlation matrix
plt.figure(figsize=(10, 8))
sns.heatmap(correlation_matrix, annot=True, cmap='coolwarm', fmt='.2f', linewidths=0.5)
plt.title('Correlation Matrix')
plt.show()
Insights and Interpretation
- Identifying Marketing Effectiveness:
- Seasonality and Trends:
- Outlier Detection:
Analyze which marketing channels or campaigns correlate strongly with sales or other KPIs.
Detect seasonal patterns or trends in media spend and sales data that may influence marketing strategies.
Identify unusual data points that may skew analysis results and warrant further investigation.
Building a Media Mix Model
Now that you’ve conducted exploratory data analysis (EDA) and gained insights, it’s time to build a media mix model using Python. We’ll cover regression analysis basics and guide you through creating a linear regression model, helping identify key business opportunities.
Introduction to Regression Analysis
Regression analysis is a statistical technique used to model the relationship between a dependent variable (e.g., sales) and one or more independent variables (e.g., media spend on different channels). It helps quantify the impact of each independent variable on the dependent variable.
Building a Simple Linear Regression Model
- Preparing Data:
- Splitting Data:
Ensure your data is in a format suitable for regression analysis, with the dependent variable (e.g., sales) and independent variables (e.g., media spend on different channels).
Divide your dataset into training and testing sets to evaluate the model’s performance.
from sklearn.model_selection import train_test_split
# Define independent variables (X) and dependent variable (y)
X = merged_data[['media_spend_tv', 'media_spend_radio', 'media_spend_digital']]
y = merged_data['sales']
# Split data into training and testing sets (80% training, 20% testing)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
- Fitting the Model:
Train a linear regression model using the training data to learn the coefficients that best fit the relationship between media spend and sales.
from sklearn.linear_model import LinearRegression
# Initialize the linear regression model
model = LinearRegression()
# Fit the model on the training data
model.fit(X_train, y_train)
- Interpreting Model Coefficients:
Once the model is trained, examine the coefficients to understand how each independent variable (media spend on different channels) contributes to predicting the dependent variable (sales).
# Coefficients of the model
coefficients = model.coef_
intercept = model.intercept_
print("Coefficients:", coefficients)
print("Intercept:", intercept)
- Making Predictions:
Use the trained model to predict the testing set and evaluate its performance using metrics like mean squared error (MSE) or R-squared.
# Predictions on the test set
y_pred = model.predict(X_test)
# Evaluate model performance
from sklearn.metrics import mean_squared_error, r2_score
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R-squared:", r2)
Example Python Code Snippet
Here’s a simplified example demonstrating the above steps:
# Import necessary libraries
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error, r2_score
# Load data
merged_data = pd.read_csv('merged_data.csv')
# Define independent variables (X) and dependent variable (y)
X = merged_data[['media_spend_tv', 'media_spend_radio', 'media_spend_digital']]
y = merged_data['sales']
# Split data into training and testing sets (80% training, 20% testing)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Initialize the linear regression model
model = LinearRegression()
# Fit the model on the training data
model.fit(X_train, y_train)
# Predictions on the test set
y_pred = model.predict(X_test)
# Evaluate model performance
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
print("Mean Squared Error:", mse)
print("R-squared:", r2)
Challenges and Limitations
Despite its benefits, media mix modeling comes with challenges and limitations that marketers and analysts must navigate. Additionally, while Python is a powerful tool for data analysis and modeling, it has specific limitations when applied to media mix modeling tasks.
Common Challenges in Media Mix Modeling
- Data Availability and Quality:
- Attribution Complexity:
- Seasonality and External Factors:
- Model Complexity vs. Interpretability:
- Budget Constraints:
Obtaining comprehensive and accurate data across all marketing channels and sales metrics can be challenging. Incomplete or inconsistent data can lead to biased results and inaccurate conclusions.
Properly attributing conversions or sales to specific marketing channels, especially in multi-touchpoint customer journeys, requires sophisticated attribution models and robust data integration.
Fluctuations in sales due to seasonal trends or external factors (e.g., economic conditions, competitor activities) can complicate the modeling process and require careful consideration during analysis.
Balancing the complexity of models (e.g., machine learning algorithms) with their interpretability is crucial. Complex models may offer higher predictive accuracy but can be harder to interpret and explain to stakeholders.
Limited marketing budgets may restrict the ability to test and optimize various media mix strategies, affecting the model’s effectiveness in recommending optimal allocations.
Limitations of Using Python for Media Mix Modeling
- Speed and Performance:
- Model Deployment:
- Domain-Specific Libraries:
- Learning Curve:
While Python is efficient for many data tasks, handling very large datasets or complex computations may require optimization or alternative approaches to maintain performance.
Moving from prototyping in Python to deploying models in production environments may involve challenges in integration with existing systems or software.
While Python’s ecosystem is vast, domain-specific libraries or algorithms tailored specifically for media mix modeling may be limited compared to other specialized tools or languages.
Python’s versatility means it can be used for various tasks beyond media mix modeling, but mastering its libraries and syntax for specific applications may require time and expertise.
Addressing Challenges and Mitigating Limitations
- Data Quality Assurance:
- Advanced Modeling Techniques:
- Collaboration and Interdisciplinary Teams:
- Continuous Evaluation and Iteration:
Invest in data governance practices and data quality assurance measures to ensure the accuracy and completeness of input data.
Explore advanced statistical techniques and machine learning algorithms that can handle complex relationships and improve model accuracy.
Collaborate with marketing, data science, and analytics teams to leverage diverse expertise and insights in modeling efforts.
Regularly validate and update models based on new data and changing market conditions to ensure relevance and reliability.
Conclusion
The collaboration of media mix modeling (MMM) and Python unlocks a world of possibilities for data-driven marketers. By leveraging Python’s user-friendly libraries, you can build and interpret MMM models, shedding light on the true impact of your marketing mix on sales. This can include deeper insights into metrics like Customer lifetime value, helping shape long-term strategies. No longer will you be left guessing about ROI – you’ll have concrete data to optimize your budget allocation, refine campaigns, and achieve sustainable marketing success.
Remember, MMM is a powerful tool but a journey, not a destination. Embrace continuous learning, experiment with different approaches, and prioritize high-quality data to ensure your model remains insightful.
Are you ready to transform your marketing strategy and unlock the hidden potential of your marketing mix?
Contact us at info@diggrowth.com to learn more about how we can help you leverage the power of Python-powered MMM and achieve your marketing goals.
Ready to get started?
Increase your marketing ROI by 30% with custom dashboards & reports that present a clear picture of marketing effectiveness
Start Free Trial
Experience Premium Marketing Analytics At Budget-Friendly Pricing.

Learn how you can accurately measure return on marketing investment.

How Predictive AI Will Transform Paid Media Strategy in 2026
Paid media isn’t a channel game anymore, it’s...
Read full post post
Don’t Let AI Break Your Brand: What Every CMO Should Know
AI isn’t just another marketing tool. It’s changing...
Read full post post
From Demos to Deployment: Why MCP Is the Foundation of Agentic AI
A quiet revolution is unfolding in AI. And...
Read full post postFAQ's
Media mix modeling is a statistical analysis technique used to determine the optimal allocation of advertising budgets across various media channels to maximize return on investment (ROI).
Python offers extensive libraries like Pandas, NumPy, and Scikit-learn that streamline data manipulation, statistical analysis, and machine learning tasks crucial for media mix modeling. Its versatility and community support make it ideal for handling complex datasets and models.
Challenges include ensuring data quality across diverse channels, accurately attributing conversions to marketing touchpoints, managing external factors' influence, balancing model complexity with interpretability, and optimizing budgets under constraints.
Media mix modeling enables businesses to make data-driven decisions by identifying the most effective marketing channels, optimizing budget allocations, improving ROI, and gaining insights into customer behavior and market trends.
Best practices include starting with clean and comprehensive data, using advanced attribution models, integrating external factors into analysis, maintaining model transparency for stakeholder buy-in, and continually refining models based on new data and market changes.