
How EDA is Fueling the Future of Marketing Analytics
Exploratory Data Analysis (EDA) is a powerful technique for marketers to make informed decisions in the ever-changing marketing landscape. Discover how EDA helps understand consumer behavior, optimize campaigns, and leverage machine learning for predictive insights.
In a dynamic marketing world, a deeper understanding of the customer can be the edge you need. Gut instinct isn’t going to give you that edge, because it’s based on prior experience, and we’re not living in times when anyone has experience to draw upon.
So, it’s more important than ever to rely on data and analytics because that gives you the truth about what actually happening and what might happen, as opposed to what you think.
According to WebFX, CMOs spend around 6.5% of their marketing budget on marketing analytics. In fact, 28% of marketing professionals reported that their marketing analytics data enables them to effectively track the performance of their campaigns.
Therefore, to succeed in this ever-evolving marketing landscape, you must not throw darts blindfolded. You really need better intelligence. And that is going to come from Exploratory Data Analysis (EDA). This data analytics process allows you to get a better feel of your data and identify useful patterns in it. So, let data help you understand what works, what doesn’t, and how you can optimize your marketing campaigns accordingly.
In this blog post, we’ll explore how EDA is an indispensable tool in marketing analytics, enabling marketers to unleash the full potential of their data.
Key Takeaways
- EDA drives smarter marketing decisions with accurate insights.
- Clean and organized data is essential for effective analysis.
- Visualization and analysis reveal patterns, trends, and outliers.
- Insights from EDA help optimize campaigns and audience targeting.
Different Types of Marketing Data
There are 7 types of marketing data that businesses collect to make informed decisions. These are:
Demographic Data:
This data is related to personal and geographical attributes (name, age, email address, contact number, location, employment history). It gives insights into whether the prospect fits into your ICP (Ideal Customer Profile).
- Firmographic Data
- Technographic Data
- Chronographic Data
- Intent Data
- Quantitative Data
- Qualitative Data
This data includes the company’s information (company’s name, location, number of employees, industry, company revenue) and is particularly useful for running account-based marketing campaigns.
This data refers to the information about the technology solutions, their adoption rate, and potential challenges they present for the business. Technographic data is useful for improved segmentation and lead prioritization.
This data refers to real-world events – when a company announces a recruitment drive, moves to a new location, starts a partnership with a competitor, etc, that impact individuals, companies, and industries. This is known as the sales trigger.
This type of data (prospect’s purchase history, search history, pages they visit, etc) reveals certain online behavior from your target audience that shows what they’re likely to do next.
This data is collected through analytics tools which are hard stat for marketers to interpret. Quantitative data includes website clicks, form completion, event appearance, email open rates, CTRs, etc.
This type of data focuses on motivations and reasons behind customers’ behavior, opinions, and desires. Qualitative data includes social media activity, notes from previous conversations, questionnaire completion, product feedback, etc.
What is Exploratory Data Analysis?
EDA is a data analytics technique to understand data in-depth and understand different data characteristics, often implying data visualization methods. It helps to identify how best to manipulate data sources to extract desired insights and get the answers you need.
It also helps to:
- Discover patterns, test a hypothesis, spot anomalies, or check assumptions.
- See what data can indicate beyond formal modeling or hypothesis testing.
- Give a better understanding of data set variables and the relationship between them.
- Determine if the statistical technique you’re considering for data analysis is appropriate.
- Identify new sources of data
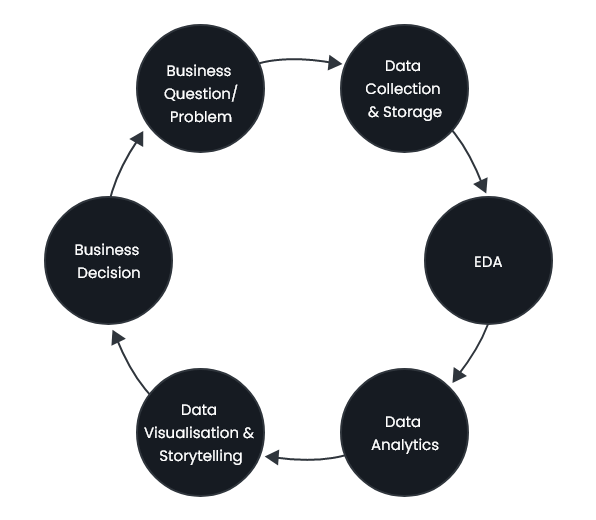
Exploratory Data Analysis Methods and Techniques
Now that we’ve established what EDA is, let’s take a look at the methods to perform it.
- Collecting Data
- Surveys and questionnaires
- Customer feedback
- Sales data
- Web analytics
- Social media data
- CRM data
- Customer loyalty programs
- Market research reports
- Finding All Variables
- Cleaning the Dataset
- Identify Correlated Variables
- Using Descriptive Statistics
- Using Clustering and Outlier Detection
- Data Visualization and Analyzing Results
In marketing analytics, the process of gathering and analyzing accurate data from various sources to find solutions to challenges, trends, possibilities, etc to evaluate the possible outcome is known as data collection. Here are some common data collection methods and sources:
When the analysis process starts, the prime focus is on the data sets that give a lot of information. This information involves changing values about various features or characteristics, which helps to understand and get valuable insights from them. For this, you need to identify the important variables which affect the outcome and their possible impact.
The next step involves cleaning the data set, which may contain null values and irrelevant information. By removing irrelevant data, you can save time and reduce the computational power needed for analysis.
Using correlated analysis, you can analyze the relationship between variables. This analysis helps in feature selection and in building predictive models based on the nature of the data and the type of correlation being assessed. Common correlation techniques include Spearman’s rank correlation coefficient, Pearson’s correlation coefficient, and Kendall’s tau correlation coefficient. Overall, correlation techniques have broad applications across diverse fields, enabling professionals and researchers to gain valuable insights and make informed decisions based on the relationships between variables in their respective domains.
It includes calculating summary statistics such as mean, median, mode, standard deviation, and variance to gain insights into the distribution of data. The mean is the average value of the data set and gives an idea of the central tendency of the data. The median is the mid-value in a sorted list of values and gives another measure of central tendency.
Clustering methods are powerful tools for identifying patterns and relationships within datasets by grouping similar data points based on their characteristics. The different types of clustering methods are K-means clustering, hierarchical clustering, and DBSCAN clustering. They help in data exploration, segmentation, and pattern recognition in various domains. Outliers are data points that vary or deviate greatly from the rest of the data and can have a critical impact on the accuracy of models. Identifying and removing outliers from data using methods like Z-score, interquartile range (IQR), and box plots method can help enhance the data quality and the models’ accuracy.
After completing the analysis process, it is important to observe the findings cautiously and carefully through data visualization to ensure proper interpretation. Data visualization involves creating visual representations of the data using graphs, charts, and other graphical techniques. Data visualization allows a quick and easy understanding of patterns and relationships within data. Visualization techniques include scatter plots, histograms, heatmaps, and box plots, etc.
Types of Exploratory Data Analysis
Several types of exploratory data analysis can be used to gain insights into data. Some common types of EDA include:
- Univariate Non-Graphical
- Multivariate Non-Graphical
- Univariate Graphical
- Multivariate Graphical
This technique aims to uncover the underlying distribution or pattern in the data, providing objective insights about the population. The procedure involves analyzing various attributes of the population distribution, such as spread, central tendency, skewness, and kurtosis.
It involves understanding the relationship between multiple variables through techniques like cross-tabulation and statistical analysis. This analysis is particularly beneficial when working with datasets that contain multiple variables and you want to understand their interrelationships and connection.
This technique focuses on analyzing individual variables in the dataset. It involves calculating summary statistics, creating frequency distributions, and generating visualizations such as histograms, box plots, and bar charts to understand the distribution and characteristics of a single variable.
Multivariate analysis involves the simultaneous examination of three or more variables in the dataset. Techniques such as scatterplot matrices, parallel coordinate plots, and heatmaps are used to visualize relationships and patterns among multiple variables. Principal Component Analysis (PCA) and Factor Analysis are commonly employed for dimensionality reduction and identifying latent variables in the dataset.
How to Boost Your Marketing Analytics Efforts Leveraging EDA
Data-driven decision-making has become crucial for success. Exploratory Data Analysis (EDA) is a powerful technique that can significantly boost your marketing analytics efforts by uncovering valuable insights from your data.
- Analyze Purchase Patterns and Preferences
- Understanding Customer Journeys and Touchpoints
- Identifying Market Segments Based on Behavior
- Analyzing Conversion Rates and Customer Engagement
- Optimizing Marketing Strategies Based on EDA Insights
EDA helps marketers understand consumers’ buying behavior, including the products or services they prefer, the frequency of purchases, and the factors influencing their decision-making process.
EDA allows marketers to map and analyze customer journeys, identifying the touchpoints where consumers interact with their brand. This insight helps optimize marketing efforts and improve the overall customer experience.
By analyzing behavioral data, marketers can identify distinct market segments with similar characteristics, needs, and preferences. EDA helps in segmenting the target audience effectively and tailoring marketing strategies for each segment.
EDA helps marketers measure conversion rates at different stages of the marketing funnel and understand customer engagement metrics, such as click-through rates, bounce rates, and time spent on a website or content.
By uncovering patterns and creating winning b2b Campaigns, marketers can identify areas for improvement and make data-driven decisions to optimize marketing strategies, allocate resources effectively, and achieve better results.
Best Practices for Taking Your Marketing Analytics Efforts Up a Notch
It’s essential to understand that effective data exploration is a key driver of informed decision-making and successful marketing strategies. By incorporating the following best practices into your EDA workflow, you can maximize the value of your marketing analytics efforts.
- Utilize advanced analytics tools and software for efficient data exploration and visualization.
- Incorporate machine learning techniques for predictive insights and accurate forecasting.
- Adopt a continuous and iterative approach to EDA for up-to-date insights.
- Focus on relevant variables to extract meaningful insights efficiently.
- Collaborate cross-functionally to gain diverse perspectives and incorporate additional data sources.
- Visualize data effectively using charts, graphs, and interactive dashboards for clear communication.
- Document and share findings to promote transparency, collaboration, and reproducibility.
The Process of Exploratory Data Analysis
- Collect & Understand Data: Gather data and examine variables.
- Clean & Preprocess: Handle missing values and inconsistencies.
- Visualize Data: Use charts and graphs to spot patterns.
- Summary Statistics: Calculate mean, median, variance, and distribution.
- Select & Extract Features: Identify key variables for analysis.
Techniques for data manipulation and interpretation
Let’s take a closer look at each step:
- Data collection and understanding the dataset
- Data cleaning and preprocessing techniques
- Data visualization for initial insights
- Descriptive statistics and summary statistics
- Feature selection and extraction methods
The first step in EDA is to carefully collect the relevant data and gain a comprehensive understanding of the dataset. This involves identifying the variables, their types, and their relationships in the dataset. It is crucial to have a clear understanding of the data in order to perform effective analysis and draw meaningful conclusions.
Once the dataset is collected, it is important to clean the data by addressing missing values, outliers, and any inconsistencies. Data preprocessing techniques such as normalization, feature scaling, and handling categorical variables may also be applied to prepare the data for analysis.
Data visualization plays a significant role in EDA as it helps to explore the patterns, trends, and distributions within the dataset. Visualizations such as histograms, scatter plots, and box plots provide valuable insights and can help identify potential outliers or relationships between variables.
Descriptive statistics provide a summary of the main characteristics of the dataset, such as mean, median, standard deviation, and quartiles. Summary statistics help in understanding the central tendencies, distributions, and variations within the data.
Feature selection involves identifying and selecting the most relevant features from the dataset that are likely to have a significant impact on the analysis. Feature extraction techniques may be used to transform and reduce the dimensionality of the dataset, extracting meaningful information from the available features.
Techniques for data manipulation and interpretation
EDA involves the use of various techniques and tools for data manipulation and interpretation. This includes data transformation, aggregation, filtering, and handling missing values. These techniques aid in exploring the dataset from different angles and uncovering hidden patterns or relationships.
- Data Visualization in EDA
- Importance of visualizing data in EDA
Data visualization plays a crucial role in Exploratory Data Analysis (EDA) as it enables us to make sense of the data by presenting it in a visual context. Through visualizations, we can gain valuable insights and discover patterns, outliers, and trends that may not be apparent from raw data alone.
Visualizing data in EDA helps us to understand the underlying structure and relationships within the data. It allows us to communicate complex information in a concise and intuitive way, making it easier for stakeholders to grasp the key findings.
Graphical techniques for data visualization
In EDA, we employ various graphical techniques to represent data visually. Some commonly used techniques include scatter plots, histograms, box plots, and many others. Each technique serves a specific purpose and helps us to uncover different aspects of the data.
- Choosing appropriate visualizations based on data types and objectives
- Using visualization to identify patterns, outliers, and trends
When visualizing data in EDA, it is essential to select the appropriate visualization techniques based on the nature of the data and the objectives of the analysis. For example, scatter plots are ideal for exploring the relationship between two continuous variables, while histograms are useful for analyzing the distribution of a single variable.
Visualizations provide us with a powerful tool to identify patterns, outliers, and trends in the data. By visualizing the data, we can quickly detect any unusual observations or trends that may require further investigation. This helps us to gain a deeper understanding of the data and uncover valuable insights.
Techniques and Tools for EDA
In exploratory data analysis (EDA), various techniques and tools are employed to gain insights from the data. These techniques help in understanding the underlying patterns and relationships in the data, enabling data scientists to make informed decisions. Additionally, the tools used in EDA simplify the process of analyzing and visualizing the data.
Statistical analysis techniques in EDA
Statistical analysis is a fundamental part of EDA. It involves examining the distribution of variables, analyzing their relationship with each other, and identifying outliers. Some commonly used statistical techniques in EDA include:
- Correlation analysis
- Hypothesis testing
- ANOVA (Analysis of Variance)
- T-tests
Importance of data cleaning and preprocessing
Data cleaning and preprocessing are crucial steps in EDA. Before conducting any analysis, it is essential to remove inconsistencies, errors, and outliers from the data. Additionally, preprocessing techniques such as normalization, feature scaling, and imputation of missing values ensure that the data is in the right format for analysis.
- Handling missing data in EDA
Missing data is a common issue in real-world datasets. In EDA, handling missing data is necessary to prevent biased or inaccurate analyses. Imputation methods, such as mean imputation, regression imputation, or multiple imputation, can be used to fill in the missing values based on patterns in the available data.
Tools for Exploratory Data Analysis
- DiGGrowth: A marketing-focused analytics platform that helps marketers collect, visualize, and interpret data. It simplifies identifying patterns, tracking campaign performance, and making informed marketing decisions.
- Pandas: A powerful library for data manipulation and analysis. It allows marketers to clean datasets, organize variables, and perform descriptive statistics for deeper insights.
- Tableau: A business intelligence tool that enables marketers to create interactive dashboards and visualizations. It helps spot trends, understand customer behavior, and communicate insights effectively.
- OpenRefine: A data cleaning and preparation tool that manages inconsistencies, handles missing values, and structures raw data for accurate analysis in marketing campaigns.
- Seaborn: A visualization library that creates informative and attractive statistical graphs. It helps marketers identify correlations, patterns, and outliers within complex datasets.
Feature selection and extraction methods for better analysis
In EDA, feature selection and extraction techniques are used to identify the most relevant variables or create new variables that capture important information from the data. Dimensionality reduction methods like Principal Component Analysis (PCA) and feature selection algorithms like Recursive Feature Elimination (RFE) help in improving the efficiency and interpretability of the analysis.
The Bottom Line
Making informed decisions is key to staying ahead of the competition. Exploratory Data Analysis (EDA) empowers marketers to extract actionable insights, understand consumer behavior, optimize campaign performance, and leverage the power of machine learning for predictive insights.
By embracing EDA as a fundamental practice, marketers can gain a deeper understanding of their data, make data-driven decisions, and drive successful marketing campaigns in 2023 and beyond. As data continues to be at the core of marketing strategies, EDA will remain a key tool for marketers to navigate the complexities of the modern marketing landscape and achieve their goals.
Ready to Make Informed Decisions Leveraging EDA?Let’s Talk!
Our data analytics aces are equipped to join your marketing analytics journey and make it a big hit. Feel free to write to us at info@diggrowth.com and we’ll take it from there.
Ready to get started?
Increase your marketing ROI by 30% with custom dashboards & reports that present a clear picture of marketing effectiveness
Start Free Trial
Experience Premium Marketing Analytics At Budget-Friendly Pricing.

Learn how you can accurately measure return on marketing investment.
Additional Resources

How Predictive AI Will Transform Paid Media Strategy in 2026
Paid media isn’t a channel game anymore, it’s a chessboard. Search, social, programmatic, video, influencer, native,...
Read full post post
Don’t Let AI Break Your Brand: What Every CMO Should Know
AI isn’t just another marketing tool. It’s changing how we connect with customers, personalize content, and...
Read full post post
From Demos to Deployment: Why MCP Is the Foundation of Agentic AI
A quiet revolution is unfolding in AI. And it’s not happening inside research labs. For decades,...
Read full post post